Intent Formalization: A Grand Challenge for Reliable Coding in the Age of AI Agents
- Author: Shuvendu K. Lahiri, Research in Software Engineering (RiSE), Microsoft Research
TL;DR: AI can now write code, but who checks that it does what you actually meant? We argue that the key challenge is intent formalization—automatically turning vague human intent into precise, checkable specifications. Early research shows LLMs can generate useful specs, interactive formalization helps developers catch more bugs, and end-to-end pipelines can produce provably correct code from informal prose. The shift is from verification to the absence of specifications to verify against.
Abstract
Agentic AI systems can now generate code with remarkable fluency, but a fundamental question remains: does the generated code actually do what the user intended? The gap between informal natural language requirements and precise program behavior—the intent gap—has always plagued software engineering, but AI-generated code amplifies it to an unprecedented scale. This article argues that intent formalization—the translation of informal user intent into a set of checkable formal specifications—is the key challenge that will determine whether AI makes software more reliable or merely more abundant. Intent formalization offers a tradeoff spectrum suitable to the reliability needs of different contexts: from lightweight tests that disambiguate likely misinterpretations, through full functional specifications for formal verification, to domain-specific languages from which correct code is synthesized automatically. The central bottleneck is validating specifications: since there is no oracle for specification correctness other than the user, we need semi-automated metrics that can assess specification quality with or without code, through lightweight user interaction and proxy artifacts such as tests. We survey early research that demonstrates the potential of this approach: interactive test-driven formalization that improves program correctness, AI-generated postconditions that catch real-world bugs missed by prior methods, and end-to-end verified pipelines that produce provably correct code from informal specifications. We outline the open research challenges—scaling beyond benchmarks, achieving compositionality over changes, metrics for validating specifications, handling rich logics, designing human-AI specification interactions—that define a research agenda spanning AI, programming languages, formal methods, and human-computer interaction.
1. Introduction
Vibe coding—a term coined by Andrej Karpathy [1]—captures the new reality of AI-powered software development: developers describe what they want in natural language, accept AI-generated code with minimal or no review, and “forget that the code even exists.” A growing ecosystem of agentic coding tools—GitHub Copilot coding agent, Claude Code, and others—now synthesizes entire functions, modules, and systems from brief prompts, planning, writing code, running tests, and iterating—often autonomously. This represents the purest manifestation of the intent gap: the user has intent but never inspects the implementation, relying entirely on the AI to bridge the two.
But a fundamental question remains unanswered: does the generated code actually do what the user intended?
Consider a simple request: “given a list of integers, remove duplicates.”
Does this mean keep one copy of each element (e.g., [1,2,3,2,4] → [1,2,3,4])?
Or does it mean remove all elements that appear more than once, keeping only unique ones (e.g., [1,2,3,2,4] → [1,3,4])?
A human developer resolves such ambiguities through domain knowledge and conversation.
An LLM resolves them through statistical pattern-matching against training data—with no grounding in the user’s specific intent.
The result is code that looks right but may silently deviate from what the user actually wanted.
For example, a typical LLM response to this prompt produces:
# Listing 1: Plausible but wrong if the user intended to remove all numbers# that have duplicates.def remove_duplicates(numbers): return list(dict.fromkeys(numbers))This keeps one copy of each element in order: remove_duplicates([1,2,3,2,4]) returns [1,2,3,4].
But a user who meant “remove all numbers that appear more than once” [2] expected [1,3,4]—the 2 should be gone entirely.
A formal postcondition disambiguates the intent:
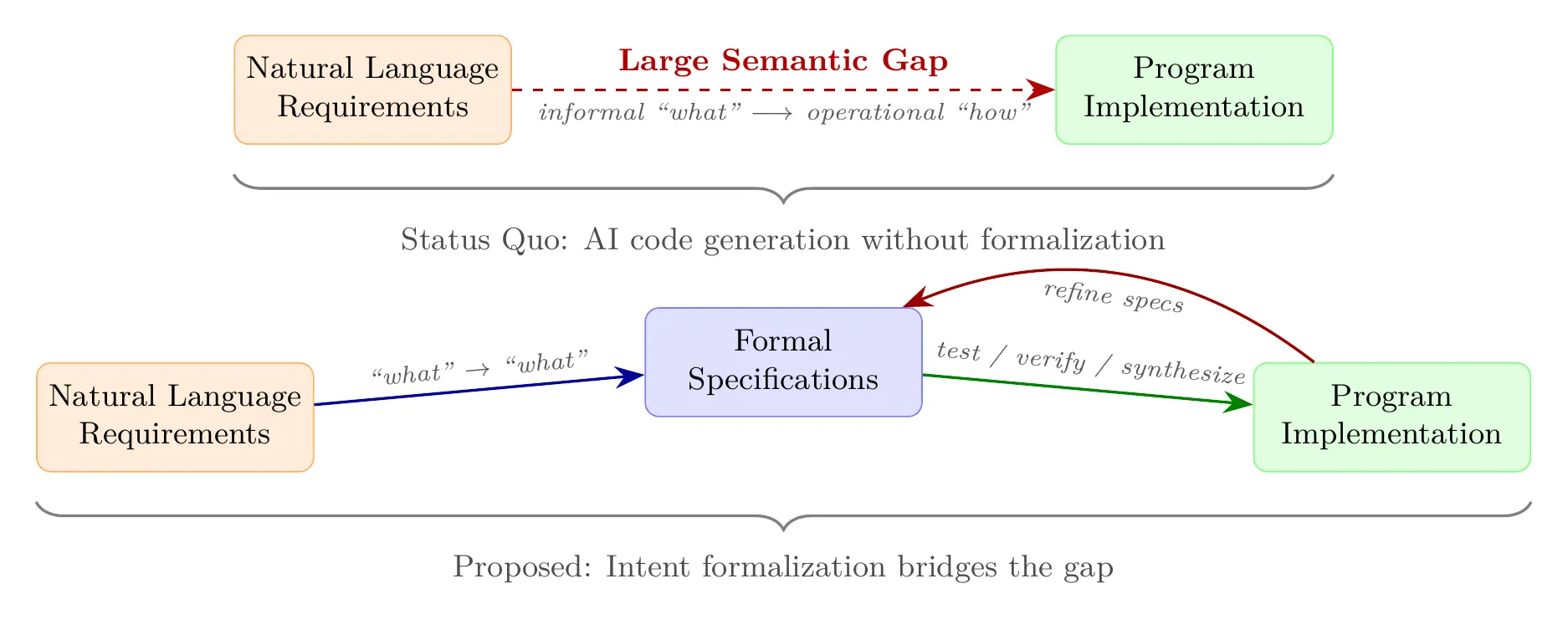
# Listing 2: A postcondition capturing the "remove elements with duplicates" intent.assert all(numbers.count(x) == 1 for x in result)assert all(x in result for x in numbers if numbers.count(x) == 1)The ambiguity in this simple example illustrates a broader phenomenon. The intent gap—the semantic distance between what a user means and what a program does—has always existed in software engineering (Figure 1), but AI amplifies it in two ways:
- Scale without scrutiny. AI generates code faster than humans can review it. The ratio of code produced to code carefully examined is growing rapidly, and traditional safeguards—code review, manual testing—cannot keep pace.
- Plausibility without correctness. LLM-generated code is plausible by construction—it looks right, compiles, and often passes a few tests—but it is not correct by construction. Subtle errors hide behind surface-level fluency, making AI-generated bugs harder to spot than hand-written ones.
We argue that the path to reliable AI-generated code is not better code generation—it is intent formalization: the automatic translation of informal user intent into checkable formal specifications. Rather than asking “can AI write the code?” we should ask “can AI help us specify what the code should do—and then verify that it does?”
Intent formalization offers a tradeoff spectrum suited to different reliability needs. At one end, lightweight specifications including tests target points of likely ambiguity—the places where different LLMs or agents would generate semantically different code from the same prompt—acting as cost-effective guardrails. In the middle, full functional specifications in verification-aware languages like Dafny, F*, and Verus enable machine-checked proofs of correctness. At the far end, domain-specific languages (DSLs) serve as complete specifications from which provably correct code is generated automatically.
This article presents a framework for intent formalization, surveys early research that demonstrates its promise, and outlines the open problems that define a research agenda for the next decade. The goal is to make a case for sustained investment by the research community and industry in intent formalization as a first-class research priority.
1.1 Why Now?
The need for intent formalization was recognized with the advent of the first generation of neural code-generation models (TiCoder [3]). OpenAI Codex (back in 2021) demonstrated that LLMs could produce syntactically correct code from natural language prompts—but also revealed how easily plausible code could silently deviate from the user’s intent. At that stage, however, AI coding tools were primarily autocomplete assistants: they suggested individual lines or small blocks of code, and the developer retained full control, reviewing each suggestion before accepting it. The human remained the primary author; the AI was a productivity aid.
Since then, the landscape has transformed dramatically. Agentic coding tools autonomously write, test, and debug entire features. Vibe coding [1] encourages developers to describe intent and “let the AI handle it.” The human has shifted from author to supervisor—and in many vibe coding scenarios, to a passive consumer of AI-generated code.
This shift has three consequences that make intent formalization critical:
- Human review is being bypassed. When developers accept AI-generated code with minimal or no review, the traditional human safeguard against intent violations disappears. Formal specifications become the only scalable mechanism for checking that generated code matches user intent.
- The attack surface has exploded. AI-generated code is entering production at unprecedented scale—including safety-critical and security-sensitive systems. A single specification gap in a parser, an authentication module, or a financial transaction handler can have outsized consequences.
- The technology is ready. The same LLMs that power vibe coding can also generate specifications. Verification infrastructure (SMT solvers, proof assistants, type systems) has matured over decades. For the first time, it is feasible to close the loop: generate code, generate specifications, and verify one against the other—all within an AI-assisted workflow.
2. What Is Intent Formalization?
We define intent formalization as the problem of automatically translating informal user intent into a set of formal, checkable program specifications. The resulting specifications span a spectrum of increasing expressiveness (Figure 2):

- Tests (input/output examples): concrete behavioral expectations, e.g.,
remove_duplicates([1,2,3,2,4])should return[1,3,4]. - Code contracts (assertions, pre/postconditions, invariants): executable specifications checked dynamically at runtime, from inline assertions such as
assert all(nums.count(x)==1 for x in res)to function-level postconditions and class invariants. - Logical contracts: specifications in verification-aware languages such as Dafny [4], F* [5], and Verus [6] that use quantifiers, ghost variables, and recursive predicates. These require a program verifier (e.g., an SMT solver) to check statically for all possible inputs.
- Domain-specific languages (DSLs): complete formal specifications in a specialized notation from which provably correct code is generated automatically via verified compilation or synthesis.
Crucially, intent formalization is not restricted to verification-aware languages—tests and code contracts apply to any mainstream language (Python, Java, C++, Rust). Verification-aware languages such as Dafny and Verus can offer stronger guarantees through machine-checked proofs, and domain-specific languages go further still—serving as complete specifications from which correct code is synthesized automatically. The first two levels of the spectrum, however, are language-agnostic and immediately deployable.
Tests and code contracts can be checked dynamically—by running the program. Logical contracts require static verification via a program verifier, offering stronger guarantees but demanding more sophisticated specifications and tooling. DSLs occupy the far end of the spectrum: the specification is complete enough that correct code is synthesized automatically via verified compilation (Section 3.4). A key insight is that these levels are not alternatives—they are complementary, and progress at any level enables progress at the others. For instance, tests can validate postconditions, postconditions can guide invariant discovery, and invariants can anchor full proofs. Intent formalization is not just limited to code generation. Even a test oracle—the expected output for a single test input—is an instance of intent formalization [7].
Two important distinctions. Not autoformalization. Intent formalization is distinct from autoformalization—the translation of complete natural language specifications into formal logic [8]. Autoformalization seeks full fidelity to a complete source text; intent formalization offers a cost-effective spectrum—from disambiguating the most ambiguity-prone properties of an inherently incomplete NL prompt to domain-specific languages from which correct code is synthesized automatically.
Complementary to spec-driven development. Tools like GitHub Spec Kit [9] structure AI coding around natural language requirements, improving traceability. But these specifications remain informal and uncheckable. Intent formalization closes this gap by producing formal, checkable specifications that can be mechanically verified against generated code.
2.1 Specifications vs. Verification
It is important to distinguish specifications from verification. Specifications describe what the code should do; verification checks that the code actually does it.
- Testing verifies specifications against finitely many inputs. It is lightweight and widely applicable, but inherently incomplete: passing all tests does not guarantee correctness on unseen inputs.
- Runtime checks verify specifications on every execution in production. Postconditions and assertions are evaluated at runtime, catching violations as they occur. This provides stronger coverage than offline testing but incurs runtime overhead and only detects errors when they are triggered.
- Proofs verify specifications against all possible inputs. They are generated by SMT solvers [10] or proof assistants and provide mathematical guarantees, but require richer specifications and more sophisticated automation.
Intent formalization focuses on the specification side: once specifications are in hand, existing verification infrastructure—test runners, SMT solvers, proof assistants—can check them.
A key bottleneck today is the absence of formal specifications to verify against. While verification technology itself continues to advance, specifications are a prerequisite—verification tools remain idle without them. Intent formalization provides a tradeoff spectrum: even targeted specifications at points of likely ambiguity serve as cost-effective guardrails [3], and teams can invest further—through full functional specifications for formal verification—as reliability needs demand.
3. Early Research on Intent Formalization
Intent formalization is not a speculative direction. Multiple independent lines of early research—primarily on benchmark problems—provide concrete evidence of the promise of this approach. We organize this evidence along four dimensions, progressing from individual capabilities to end-to-end systems.
3.1 LLMs Can Generate Meaningful Specifications
LLMs prompted with natural language descriptions can generate postconditions—executable assertions that constrain function outputs for arbitrary inputs [2]. On the Defects4J benchmark [11] (hundreds of real bugs across large Java projects), LLM-generated postconditions caught one in eight real bugs, including bugs missed by the classic Daikon invariant detector [12]. GPT-4 generated postconditions with substantially higher soundness and completeness scores than GPT-3.5 or CodeLlama, suggesting that specification quality scales with model capability.
Beyond function-level postconditions, ClassInvGen [13] synthesizes class invariants—the key properties that hold an entire module together—for C++ data structures. A single well-chosen class invariant can replace hundreds of function-level specifications, making review tractable and surfacing the crucial non-trivial properties that practitioners care about most. ClassInvGen outperforms both direct LLM prompting and Daikon on this task. VeriStruct [14] scales further to entire data-structure modules in Verus, verifying nearly all functions across 11 modules including linked lists, hash maps, and B-trees.
These results establish that LLMs can produce specifications encoding real semantic understanding, not just syntactic patterns.
But a prior question arises: how do we measure whether generated specifications are good enough?
3.2 Measuring Specification Quality
A fundamental challenge for intent formalization is that there is no oracle for specification correctness other than the user. Code can be tested against specifications, but who tests the specifications? Unlike code, where test suites provide an independent check, a generated specification has no ground truth to compare against—the user’s intent exists only in the user’s head. This makes validating specifications one of the foremost open problems.
We advocate for automated metrics grounded in two properties [2], [15]:
- Soundness: the specification is consistent with correct behavior—it does not reject valid implementations.
- Completeness: the specification is discriminating—it rejects incorrect implementations.
One approach [15] operationalizes these properties using only tests (input/output pairs), without requiring the code itself:
- A specification S is sound with respect to a test suite T if S is satisfied on every test (i, o) ∈ T.
- A specification S is complete with respect to T if, for each test (i, o) ∈ T, S fails when the output o is replaced by a mutated output o’. To accommodate non-determinism (where multiple outputs may be valid for a given input), completeness is measured as the fraction of output mutations that the specification detects.
The main challenge for soundness is assembling an exhaustive set of tests: a specification that passes a handful of tests may still reject valid behavior on untested inputs. Completeness is harder still: it requires not only that the specification capture exactly what the user means, but also that the output mutations reflect natural mistakes—the kinds of errors that humans, and increasingly AI, actually make.
Since both properties are defined in terms of evaluating a specification against tests, they can be checked before any implementation is written [2], [15]. For simple executable assertions this evaluation is straightforward, but specifications in verification-aware languages often involve quantifiers, recursive predicates, and ghost variables that cannot be directly executed. Lahiri et al. [15] address this by proposing novel symbolic techniques to evaluate such rich specifications against concrete test inputs, enabling automated soundness and completeness checking even for complex logical contracts. This provides objective, reproducible measures of specification quality—just as NL-to-Code research advanced through test-based benchmarks like HumanEval [16]. Test-based evaluation is one promising approach; other techniques—symbolic analysis, property-based testing, and targeted user interaction—may further strengthen specification validation.
As an example of the power of automated metrics, consider a GPT-4–generated Dafny specification for “common elements” labeled “strong” by expert reviewers [17]:
// Listing 3: A Dafny specification labeled "strong" by expert reviewers—but// automated completeness metrics reveal it is incomplete [15].ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))ensures forall i,j :: 0<=i<j<|result| ==> result[i] != result[j]This says every element in result appears in both inputs, and results have no duplicates—sound, but incomplete.
Automated symbolic testing [15] found that the implication (==>) should be a bi-implication (<==>): without it, the empty list trivially satisfies the specification.
The corrected version:
// Listing 4: Corrected specification with bi-implication.ensures forall x :: x in result <==> (InArray(a, x) && InArray(b, x))Across the full evaluation, automated metrics found three mislabeled and two inconsistent specifications introduced by copy-paste errors—all missed by human labeling [15]. You cannot improve what you cannot measure, and automated metrics are essential for scaling intent formalization.
These metrics also enable downstream proof automation. The Auto-Verus system [18] uses soundness and completeness metrics [15] to filter LLM-generated specifications and proofs for Rust/Verus programs, bootstrapping high-quality training data through a self-evolution cycle and achieving 3.6× higher proof accuracy than GPT-4o zero-shot.
More abundant and higher-quality specifications can enhance AI’s ability to generate proofs.
With reliable metrics in hand, we can ask whether specifications improve code generation itself—not just evaluate it after the fact. When the user must be consulted, the interaction should be optimized to maximize the number of correct specifications obtained per user query—a principle embodied by TiCoder.
3.3 Interactive Intent Formalization
The TiCoder system [3], [19] uses intent formalization interactively during code generation (Figure 3).

Rather than accepting whatever code an LLM produces, TiCoder generates candidate tests that prioritize points of ambiguity—inputs where different code candidates produce different outputs—and asks the user to classify each as “Yes,” “No,” or “Undef.” Approved tests prune incorrect candidates via code execution. This embodies the pay-as-you-go philosophy: TiCoder starts at the cost-effective end of the spectrum, targeting the tests most likely to expose where the LLM’s interpretation diverges from the user’s intent.
Sidebar: A TiCoder Interaction
Prompt: “Find the shared elements from two lists.”
Generated tests:
common([1,2,3],[2,3,4]) == [2,3]— User: Yescommon([1,2,2],[2,2,3]) == [2,2]— User: NoBy rejecting test 2, the user disambiguates that the result should be a set, not a multiset. TiCoder prunes candidates that preserve duplicates.
A small-scale controlled study with 15 professional developers on code-generation benchmarks [19] found: developers correctly evaluated AI-generated code roughly twice as often with TiCoder as without it (p < 0.001), cognitive load dropped significantly (p = 0.007), approved tests persisted as regression tests, and the majority of participants preferred TiCoder. On these benchmarks, a modest amount of intent formalization—approving a few tests—yields a significant return in correctness.
3.4 End-to-End Verified Pipelines
At the far end of the spectrum, the 3DGen system [20] demonstrates intent formalization at the DSL level, where the specification is complete enough to generate code automatically. 3DGen uses a multi-agent AI architecture to translate informal RFC prose into formal specifications in the 3D domain-specific language, with symbolic test generation providing feedback for iterative refinement. The verified 3D specifications compile via EverParse [21] into provably correct, memory-safe C or Rust binary parsers—the specification is the program, mediated by verified synthesis. It has produced verified parsers for 20 standard network protocol formats (DNS, TLS extensions, QUIC)—demonstrating the potential of the full spectrum, from informal prose through a DSL to provably correct, deployable code.
4. A Research Agenda
The early research above demonstrates promise on benchmark problems, but also reveals how far we are from a general solution. Seven open problems define the research frontier, spanning AI capabilities, formal methods infrastructure, human interaction design, and software engineering practice.
From benchmarks to real-world systems. Current results target self-contained algorithmic functions. Real-world software has side effects, mutable state, concurrency, and complex dependencies. What does a “postcondition” mean for an asynchronous event handler or a machine learning pipeline? We need benchmarks, metrics, and specification idioms for real-world intent formalization.
Change intent and compositionality. In practice, most software development involves changing existing code, not writing from scratch. Here, intent comprises not only the natural language change description—“fix this bug,” “add caching,” “handle the empty-input edge case”—but also the existing source code, tests, and specifications that define the current behavior. Intent formalization must therefore capture what should change about behavior and compose with existing specifications. A closely related challenge is code translation—for example, migrating legacy C codebases to Rust. Early work such as SpecTra [22] shows that generating intermediate informal specifications from source code and using them to guide translation significantly improves correctness. Formalizing the intent of code to be translated is crucial for reliable code translation.
Identifying what to clarify cost-effectively. For a practitioner, the value of a specification is measured by how many bugs it can prevent. We therefore need metrics for ranking specifications by their expected impact, especially when surfacing them to users for validation. TiCoder takes a first step by generating diverse code candidates and targeting tests at inputs where candidates disagree—but this requires sampling the space of plausible implementations, which becomes expensive for large code blocks or multi-function tasks. Scalable methods are needed to prioritize specifications by their bug-prevention value without exhaustively enumerating candidate programs.
Automated metrics for spec validation. Since there is no oracle for specification correctness other than the user, validating generated specifications is a foremost challenge. Progress requires incorporating multiple complementary signals: tests and mutation analysis as automated proxies [2], [15], targeted user feedback to resolve ambiguities that automation cannot settle, and cross-checking across different artifacts such as code, docstrings, and formal annotations [23].
Rich logics and quantifiers. Verification-aware languages use quantifiers, recursive predicates, and ghost variables. LLMs struggle with these constructs, and existing verifiers have fundamental limitations in unrolling recursive predicates for complex concrete test inputs, making automated soundness and completeness evaluation difficult [15].
Human-AI interaction for specification. TiCoder’s approve/reject loop significantly improves correctness on benchmark problems, but real-world specification needs richer interaction: natural language explanations of formal properties, confidence-calibrated suggestions, and specification templates—a largely unexplored HCI design space.
Integration into developer workflows. Intent formalization must integrate naturally into modern developer workflows—from issue creation, where specifications capture intended behavior before code is written; through code review, where specifications surface intent for reviewers; to CI/CD pipelines, where agentic workflows [24] continuously discover and validate specifications against evolving requirements. In the age of vibe coding, where humans may never inspect the code, specifications become the primary interface between human intent and machine behavior—making this integration not just desirable but essential.
5. Related Work
Intent formalization draws on and extends several established areas. Specification mining: classical tools like Daikon [12] infer invariants from execution traces but cannot capture user intent beyond observed behavior; LLM-based specification generation transcends this limitation by reasoning about intended semantics. LLM-based code generation: benchmarks like HumanEval [16] evaluate code correctness via pass@k but not specification quality; intent formalization shifts the evaluation target from “does code pass tests?” to “do specifications capture intent?” Formal verification: SMT solvers [10], proof assistants, and verification-aware languages (Dafny [4], Verus [6]) provide mature infrastructure for checking specifications but cannot generate them—intent formalization supplies the missing input. LLMs for verification: recent work on leveraging LLMs for program verification [25] and Dafny specification synthesis [17] focuses primarily on making verification succeed for given programs rather than capturing user intent for code that does not yet exist.
6. Conclusion
The age of AI-generated code is here; the age of reliable AI-generated code is not. We have presented early research showing that intent formalization—making user intent explicit, checkable, and enforceable through formal specifications—is a promising direction. LLMs can generate specifications across the full formalism spectrum. Automated metrics can evaluate specification quality at or above expert level. Interactive formalization significantly improves developer correctness on benchmark problems. End-to-end pipelines produce verified code from informal prose. And specification quality enables proof automation.
The open challenges—scaling beyond benchmark problems, formalizing change intent, identifying what to clarify cost-effectively, automated metrics for spec validation, handling rich logics, designing human-AI interactions, and achieving compositionality over changes—are each substantial research programs. We call on the community to treat intent formalization as a first-class priority: with dedicated benchmarks, cross-disciplinary collaboration among AI, PL, formal methods, and HCI researchers, and sustained investment. The intent gap is the bottleneck; closing it will determine whether AI makes software more reliable or merely more abundant.
Acknowledgments. This article reflects contributions from many collaborators, including Nikolaj Bjorner, Sarah Fakhoury, Saikat Chakraborty, Markus Kuppe, Shan Lu, Tahina Ramananandro, Nikhil Swamy, Aaditya Naik, Georgios Sakkas, Madeline Endres, Elizabeth Dinella, Todd Mytkowicz, Madanlal Musuvathi, and many others in the RiSE group at Microsoft Research. The material presented here draws on work published at FSE 2024 [2], FMCAD 2024 [15], IEEE TSE 2024 [19], ICSE 2025 [20], ICLR 2025 [18], SAIV 2025 [13], and TACAS 2026 [14].
References
[1] Andrej Karpathy. “Vibe Coding.” X (formerly Twitter), 2025. https://x.com/karpathy/status/1886192184808149383
[2] Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri. “Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions?” In Proceedings of the ACM International Conference on the Foundations of Software Engineering (FSE), 2024.
[3] Shuvendu K. Lahiri, Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, Madanlal Musuvathi, Piali Choudhury, Curtis von Veh, Jeevana Priya Inala, Chenglong Wang, and Jianfeng Gao. “Interactive Code Generation via Test-Driven User-Intent Formalization.” arXiv preprint arXiv:2208.05950, 2022.
[4] K. Rustan M. Leino. “Dafny: An Automatic Program Verifier for Functional Correctness.” In Logic for Programming, Artificial Intelligence, and Reasoning (LPAR), 2010.
[5] Nikhil Swamy, Cătălin Hrițcu, Chantal Keller, Aseem Rastogi, Antoine Delignat-Lavaud, Simon Forest, Karthikeyan Bhargavan, Cédric Fournet, Pierre-Yves Strub, Markulf Kohlweiss, Jonathan Protzenko, Jean-Karim Zinzindohoué, and Santiago Zanella-Beguelin. “Dependent Types and Multi-Monadic Effects in F*.” In Proceedings of the ACM SIGPLAN Symposium on Principles of Programming Languages (POPL), 2016.
[6] Andrea Lattuada, Travis Hance, Chanhee Cho, Matthias Brun, Isitha Subasinghe, Yi Zhou, Jon Howell, Bryan Parno, and Chris Hawblitzel. “Verus: Verifying Rust Programs using Linear Ghost Types.” In Proceedings of the ACM on Programming Languages (OOPSLA), 2023.
[7] Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. “TOGA: A Neural Method for Test Oracle Generation.” In Proceedings of the International Conference on Software Engineering (ICSE), 2022.
[8] Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. “Autoformalization with Large Language Models.” In Advances in Neural Information Processing Systems (NeurIPS), 2022.
[9] GitHub. “From Ambiguity to Precision: Spec Kit for GitHub Copilot.” https://developer.microsoft.com/blog/spec-driven-development-spec-kit, 2025.
[10] Leonardo de Moura and Nikolaj Bjørner. “Z3: An Efficient SMT Solver.” In Tools and Algorithms for the Construction and Analysis of Systems (TACAS), 2008.
[11] René Just, Darioush Jalali, and Michael D. Ernst. “Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs.” In Proceedings of the International Symposium on Software Testing and Analysis (ISSTA), 2014.
[12] Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin. “Dynamically Discovering Likely Program Invariants to Support Program Evolution.” In Proceedings of the 21st International Conference on Software Engineering (ICSE), 1999.
[13] Chuyue Sun, Viraj Agashe, Saikat Chakraborty, Jubi Taneja, Clark Barrett, David Dill, Xiaokang Qiu, and Shuvendu K. Lahiri. “ClassInvGen: Class Invariant Synthesis Using Large Language Models.” In Proceedings of the International Symposium on AI Verification (SAIV), Lecture Notes in Computer Science, vol. 15947, Springer, 2025.
[14] Chuyue Sun, Yican Sun, Daneshvar Amrollahi, Ethan Zhang, Shuvendu K. Lahiri, Shan Lu, David Dill, and Clark Barrett. “VeriStruct: AI-assisted Automated Verification of Data-Structure Modules in Verus.” In Proceedings of the International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), 2026.
[15] Shuvendu K. Lahiri. “Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages.” In Proceedings of the International Conference on Formal Methods in Computer-Aided Design (FMCAD), 2024.
[16] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. “Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation.” In Advances in Neural Information Processing Systems (NeurIPS), 2023.
[17] Md Rakib Hossain Misu, Cristina V. Lopes, Iris Ma, and James Noble. “Towards AI-Assisted Synthesis of Verified Dafny Methods.” In Proceedings of the ACM International Conference on the Foundations of Software Engineering (FSE), 2024.
[18] Tianyu Chen, Shuai Lu, Shan Lu, Yeyun Gong, Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Hao Yu, Nan Duan, Peng Cheng, Fan Yang, Shuvendu K. Lahiri, and Tao Xie, Lidong Zhou. “Automated Proof Generation for Rust Code via Self-Evolution.” In Proceedings of the International Conference on Learning Representations (ICLR), 2025.
[19] Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shuvendu K. Lahiri. “LLM-Based Test-Driven Interactive Code Generation: User Study and Empirical Evaluation.” IEEE Transactions on Software Engineering, 50(9):2254–2268, 2024.
[20] Sarah Fakhoury, Markus Kuppe, Shuvendu K. Lahiri, Tahina Ramananandro, and Nikhil Swamy. “3DGen: AI-Assisted Generation of Provably Correct Binary Format Parsers.” In Proceedings of the 47th International Conference on Software Engineering (ICSE), 2025.
[21] Nikhil Swamy, Tahina Ramananandro, Aseem Rastogi, Irina Spiridonova, Haobin Ni, Dmitry Malloy, Juan Vazquez, Michael Tang, Omar Cardona, and Arti Gupta. “Hardening Attack Surfaces with Formally Proven Binary Format Parsers.” In Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2022.
[22] Vikram Nitin, Rahul Krishna, and Baishakhi Ray. “SpecTra: Enhancing the Code Translation Ability of Language Models by Generating Multi-Modal Specifications.” arXiv preprint arXiv:2405.18574, 2024.
[23] Chuyue Sun, Ying Sheng, Oded Padon, and Clark Barrett. “Clover: Closed-Loop Verifiable Code Generation.” In Proceedings of the International Symposium on AI Verification (SAIV), Lecture Notes in Computer Science, Springer, 2024.
[24] GitHub. “Automate Repository Tasks with GitHub Agentic Workflows.” https://github.blog/ai-and-ml/automate-repository-tasks-with-github-agentic-workflows/, 2026.
[25] Adharsh Kamath, Nausheen Mohammed, Aditya Senthilnathan, Saikat Chakraborty, Pantazis Deligiannis, Shuvendu K. Lahiri, Akash Lal, Aseem Rastogi, Subhajit Roy, and Rahul Sharma. “Leveraging LLMs for Program Verification.” In Proceedings of the International Conference on Formal Methods in Computer-Aided Design (FMCAD), 2024.